
做一次大自然的搬运工。
写在前头
爬虫是啥?专业点说是按照一定规则自动爬取万维网信息的程序或脚本。
按照我个人的理解就是咱平常上个网的时候,会看到自己想要的数据比如图片啊文字啊什么的,看到喜欢图片就右键保存到本地,那如果有一百张喜欢的图片怎么办?一个一个点怕不是石乐志(当然那些图片对你的吸引程度真的让你石乐志当我没说)。
这时候如果刚好能很机智的发现一些如同“哇,这些图片的网址前面基本一样,只有最后的几个字符改了改”的规律,就可以写写程序或者脚本来帮你做这些事啊,毕竟机器就这么傻,喜欢干重复的事,而它干起来又很快(起码比你手动快,当然如果以后嫌慢了还是可以改进的)。
我觉得爬虫就是模拟了我们平常自己用浏览器来获得各种网上的数据的过程,当然爬虫还有很多更牛[-嘀-]的应用,就得以后慢慢学习了,这里只是用Python做个简单的实现。
预备知识
初学Python的时候,大概是因为有“本地的程序写得都快吐了,能不能让村里通一次网?”这种想法,所以爬虫真的是一个非常具有吸引力的东西。前几天师兄问群里小朋友们想学啥技术,他们说要学爬虫,所以我就只能赶紧重新回顾一下这部分内容。过去写爬虫的时候真的不知道自己写得是啥玩意,知其然不知其所以然的那种,一年的学习下来,大概觉得如果想大概明白爬虫怎么写,就得准备好这些:
- Python基本语法了解一下
- HTTP协议了解一下
- 前端知识了解一下(这个我不确定重要不重要,懂一点也行吧,起码看html和js不要有什么障碍)
- 记得联网
爬虫我也写得不多,所以有错的地方是难免的,如果有错误希望能在评论里说出来或私聊我,大家相互学习。如果你恰好没有学过爬虫,可以大概了解一下做一个简单的爬虫的一些过程。
顺便推荐一个我朋友的公众号,他会常常更新一些他用python写的一些好玩的程序和脚本,也更新一些关于常用模块的教程,微信搜索公众号“肥宅Sean”(虽然他本人并不肥宅而且还比较帅的说)。
第三方模块
其实可以用Python3自带的urllib来实现爬虫,但我觉得既然用轮子就用更好的轮子嘛,所以我还是推荐第三方模块requests,安装也很简单,如果已经装了pip直接命令行输入pip install requests,如果没有就去装一个pip。这里只是很粗浅的用了一下requests模块,我不想花费太多时间讲解这个模块,想学习就可以查官方文档或者百度一下即可。
需求
我们这次的目标是用爬虫来实现一个翻译程序,想法很简答,就是爬取有道翻译(啥翻译都差不多,过程了解一下),我不能确保看完这篇文章后写出来的程序就一定没问题,毕竟有道那边有的时候也会改一改他们的代码嘛(不要问我为什么知道),但过程应该差不多。
- 输入想翻译的内容
- 爬取有道翻译结果
- 显示出结果
正文
说了那么多废话,主要是我的一些心路历程,现在就开始吧。
抓包
第一步不是直接打开编辑器,而是先去看看有道翻译是怎么翻译的,之前说了嘛,写爬虫是为了模拟这个获取数据的过程,怎么去看这个过程呢?打开你的Chrome浏览器(如果没有就下载一个,强烈推荐这个浏览器),然后进入有道翻译的主页面:
然后按下F12或者右键点开检察,然后在出来的方框的最上面一栏选择Network:
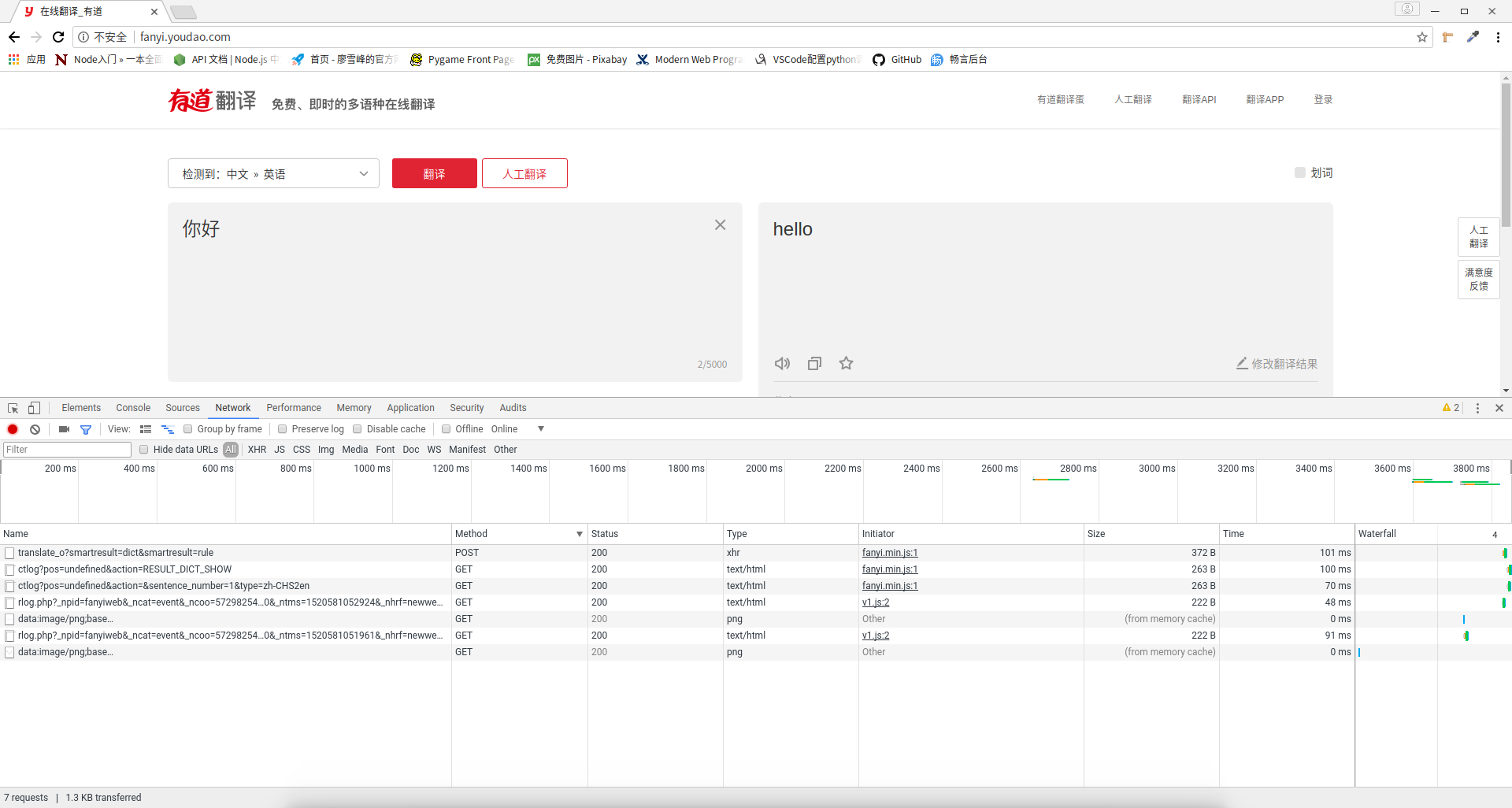
这个小窗口的东西会告诉你浏览器和服务器间的通信,当然现在还没有出现什么,在输入框那里输入你想翻译的内容,然后点击(第一次也可以不用点)“翻译”按钮,就会看到一大堆消息:
我们关注的是Method那里是POST的那一栏,你的没有Method就随便右键一个栏比如Status,会出现Method选项,点开就有了,然后点击Method那里会给这些项目排序,把POST排到最上方即可,然后点击那个POST的栏目:
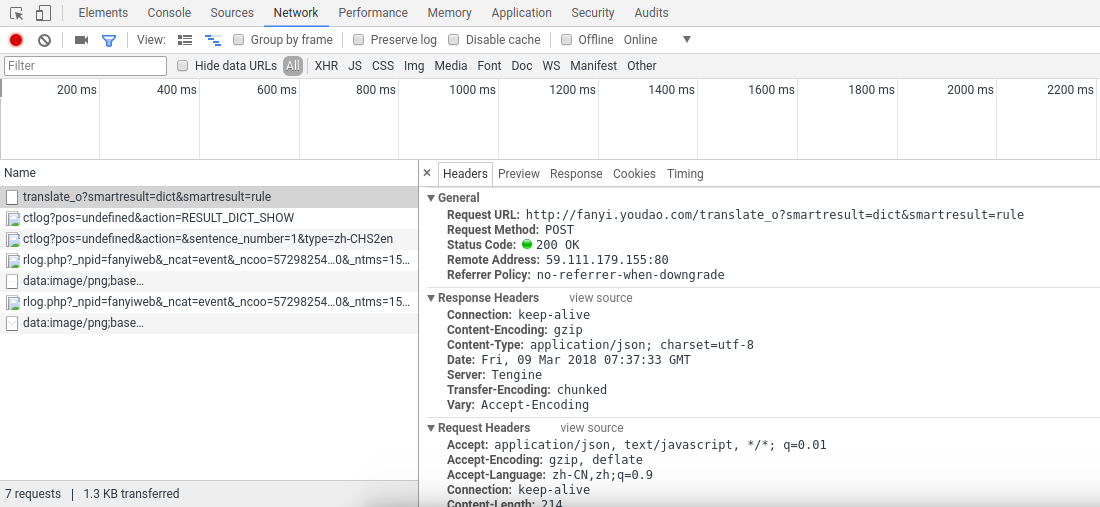
换一个方向看可能会比较完整一些。
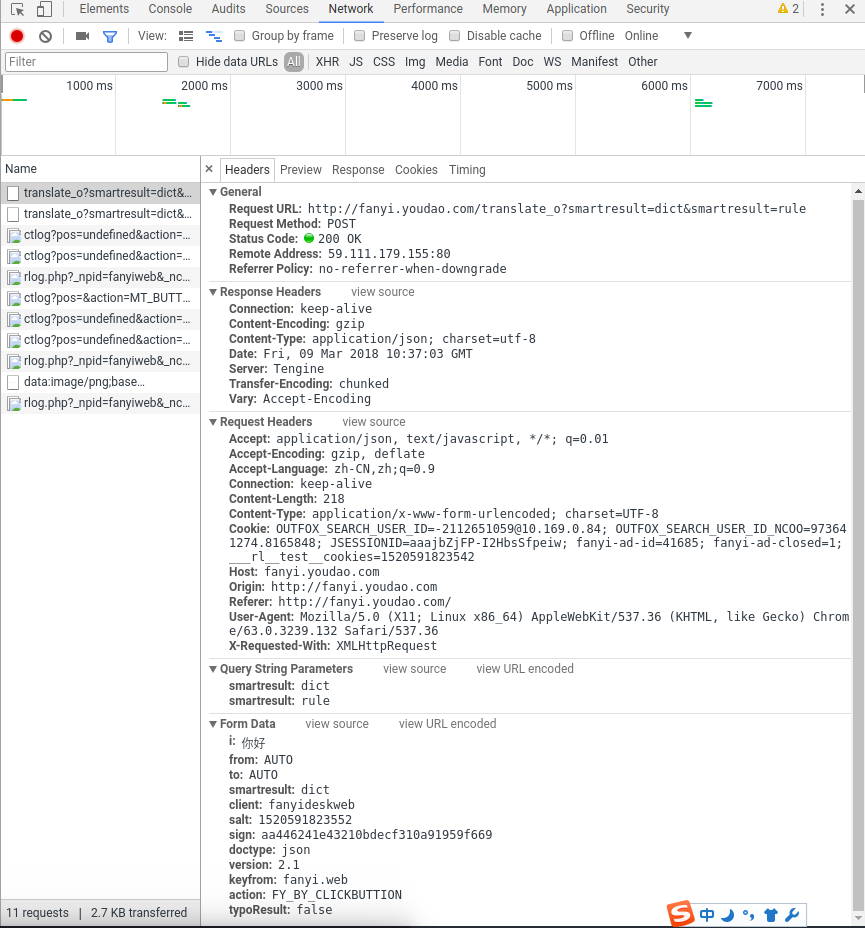
我们可以从上面看到很多信息,比如各种首部,以及Form Data,这是post提交的表单,我们可以在里面看到i属性正是我们想要翻译的内容,接着我们打开Headers旁边的Preview,可以看到服务器响应发回来的数据:
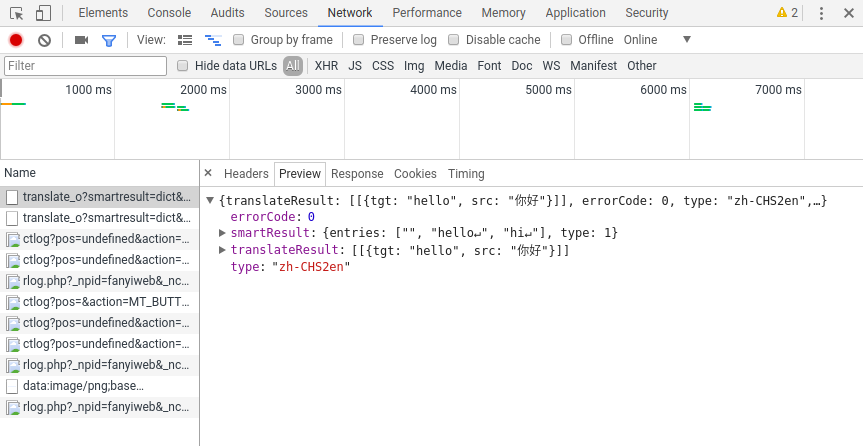
OK!你看到tgt后面的内容了吧,那正是我们想要的,可关键是我们如何用代码来实现呢?
代码实现
requests中有一个方法就是post(),它正好对应了浏览器发送请求的方式POST,这个方法有三个参数,第一个是url,即你请求资源对应的url,注意这个可不是 http://fanyi.youdao.com/ ,而应该是刚刚的Headers首部信息里通用首部的Request URL,如下图:

所以你目前可以写两行代码了:
1 | import requests |
requests.post()会返回服务器所响应的内容,不过被requests模块封装成了Response对象,可以通过response.text查看其内容,如果正确的话我们想要的是像之前在Preview里看到的那样,但我们看到了什么呢:
1 | dreamhh@dreamhh-PC:~/Documents/Code/Python3/spidy$ python3 |
相信只要有正常的英语水平都会知道这是个错误。刚也说了,requests.post()函数有三个参数,第一个是url,剩下的第二个是headers,也就是报文首部,以及data,通过POST方法要提交给服务器的数据。
后面两个参数都可以在刚刚的Headers中看到,headers参数对应Reqests Header的内容,data参数则是对应Form Data,你可以注意到这两部分都是一个个的键值对,在Python中如何存放这些键值对呢?显然就是dict了,所以下来的工作比较简单无脑,也比较繁琐(添加引号):
1 | import requests |
headers其实不是必须的,但有一些还是要添加上,你可以只添加上面那部分内容,data数据则必须一样,目前我们先测试一下你好这个词,运行一下看看效果:
1 | dreamhh@dreamhh-PC:~/Documents/Code/Python3/spidy$ python3 youdao.py |
OK!和Preview中的内容是一样的了!问题又来了,response.text是一个字符串,我们应该怎么去提取,如果使用字符串相关的函数或者正则表达式实在是有点low了,我们可以注意到这其实是一个JSON字符串(因为有道在这里用的ajax),你可以使用Python内置的json模块,但requests模块早就考虑到这点了,可以使用response.json()方法,返回Python中的dict,所以你可以这么干:
1 | # ... |
运行后:
1 | dreamhh@dreamhh-PC:~/Documents/Code/Python3/spidy$ python3 youdao.py |
这样就完美地提取出了翻译结果了!
未完待续…