
我们要做得更好。
重构
上面的代码中我们简单实现了如何爬取有道翻译的数据,我们不想只翻译这么一个结果,怎么样翻译其他的单词呢?当然是修改一下data的内容,我们第一眼看去显然是要修改i参数嘛,因为这个参数显示是你好,修改了它以后是不是就能返回其他结果呢?有了这个想法我们对代码进行修改,把功能放到函数里:
1 | import requests |
运行下看看:
1 | dreamhh@dreamhh-PC:~/Documents/Code/Python3/spidy$ python3 youdao.py |
输入你好没问题,但别的怎么会报错了呢?我们打印一下translator()中的result看看:
1 | dreamhh@dreamhh-PC:~/Documents/Code/Python3/spidy$ python3 youdao.py |
不用说,又出错了,为什么啊(事实上以前是不会错的,后来有道的程序员可能为了应对爬虫做了一些修补,但没关系,这依旧难不倒我们)?只能翻译你好我要这个程序有何用?显然是因为Form Data提交的内容有问题,这时候不要急,我们继续回到开始的抓包过程,我们多试几次输入来看看每次提交的Form Data到底有什么不一样的地方:
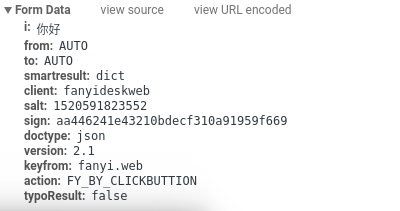
第一次输入你好:
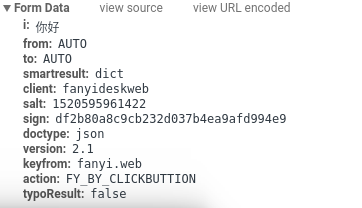
第二次输入你好:
第三次输入你好世界:
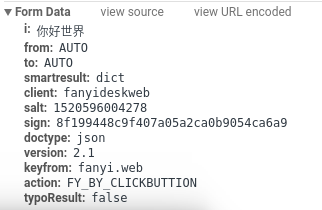
经过对比后我们发现他们的salt和sign是不一样的,即使是同样的词条也是如此,接下来我们就要思考这两个值是如何产生的了,提交表单数据之前能处理这两个值的代码显然是 javascript 代码,接下来的内容会涉及一点前端,看不懂得话就跟着操作一下也没事,实在不想看可以拉到下一部分把关键性代码复制一下。
salt和sign的产生
我们知道Form Data的产生是在点击翻译按钮之后,右键翻译按钮,并点击检查,我们可以看到它在html中的位置,更重要的是可以看到它的一些属性,我们想知道它上面添加了什么事件,点击Event Listeners:
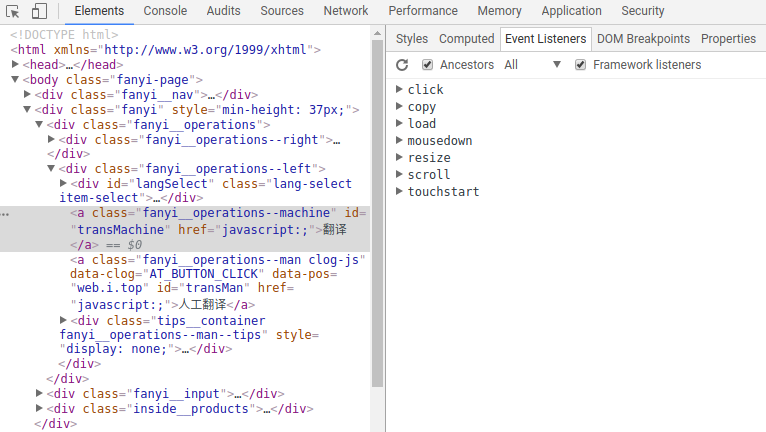
然后点开click事件:
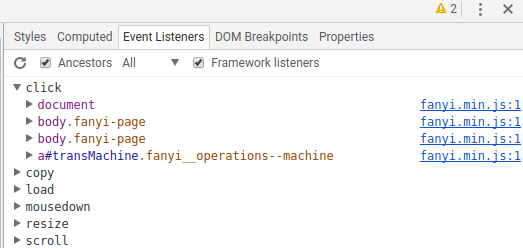
主要看第四个,第四条是添加在这个按钮上的,前三个是按钮的父元素。它的内容定义在fanyi.min.js:1中,于是我们当然是点击它咯:
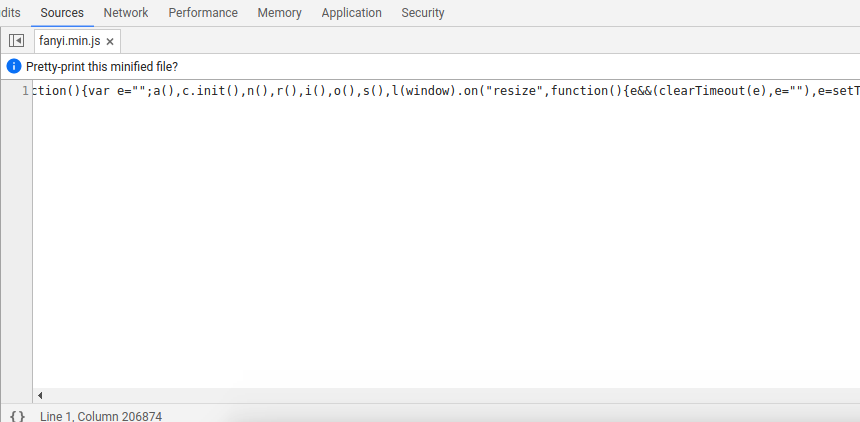
我们可以看到一行很长的代码,点击一下左下角的{},就会按照一定格式显示出这个js代码文件:
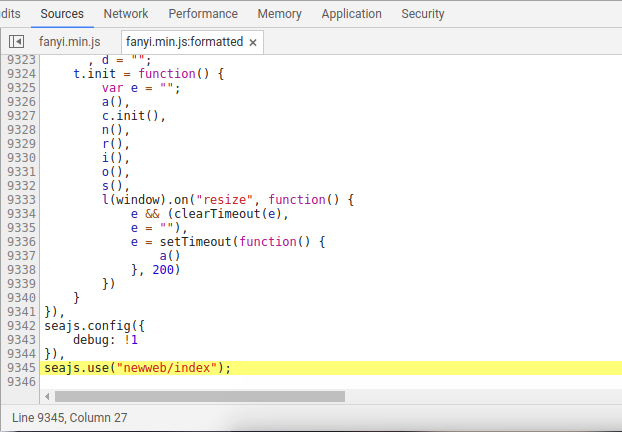
一看吓一跳,居然有9000+行,这去哪里找salt和sign啊,简直是大海捞针啊,我建议可以学习如何用浏览器调试js代码,这里我就直接说了,可以使用ctrl+f,下面会出来一个窗口,我们可以输入想要查找的内容:
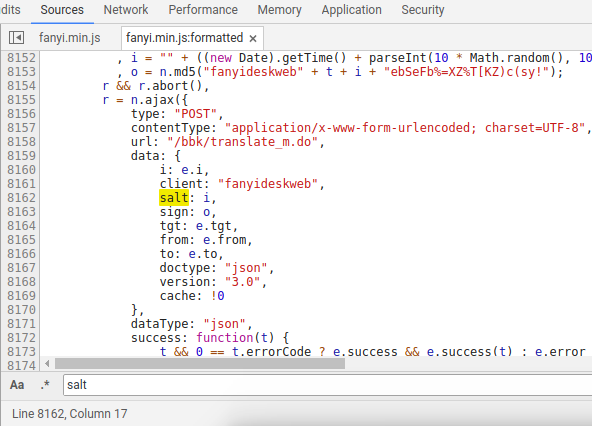
一共找到了3个salt,怎么确认哪一个是我们想要的查找的那个呢?很简单,在左侧数字那里打断点,然后点击翻译按钮,在哪一个salt所在的断点停下来了,我们要找的就是哪一个:
打断点:
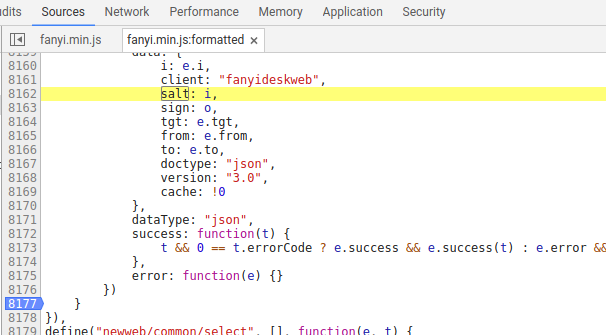
点击运行,没有停顿就换一个salt打断点,知道出现一个断点能暂停当前页面的时候(停在断点的时候背景会变暗):
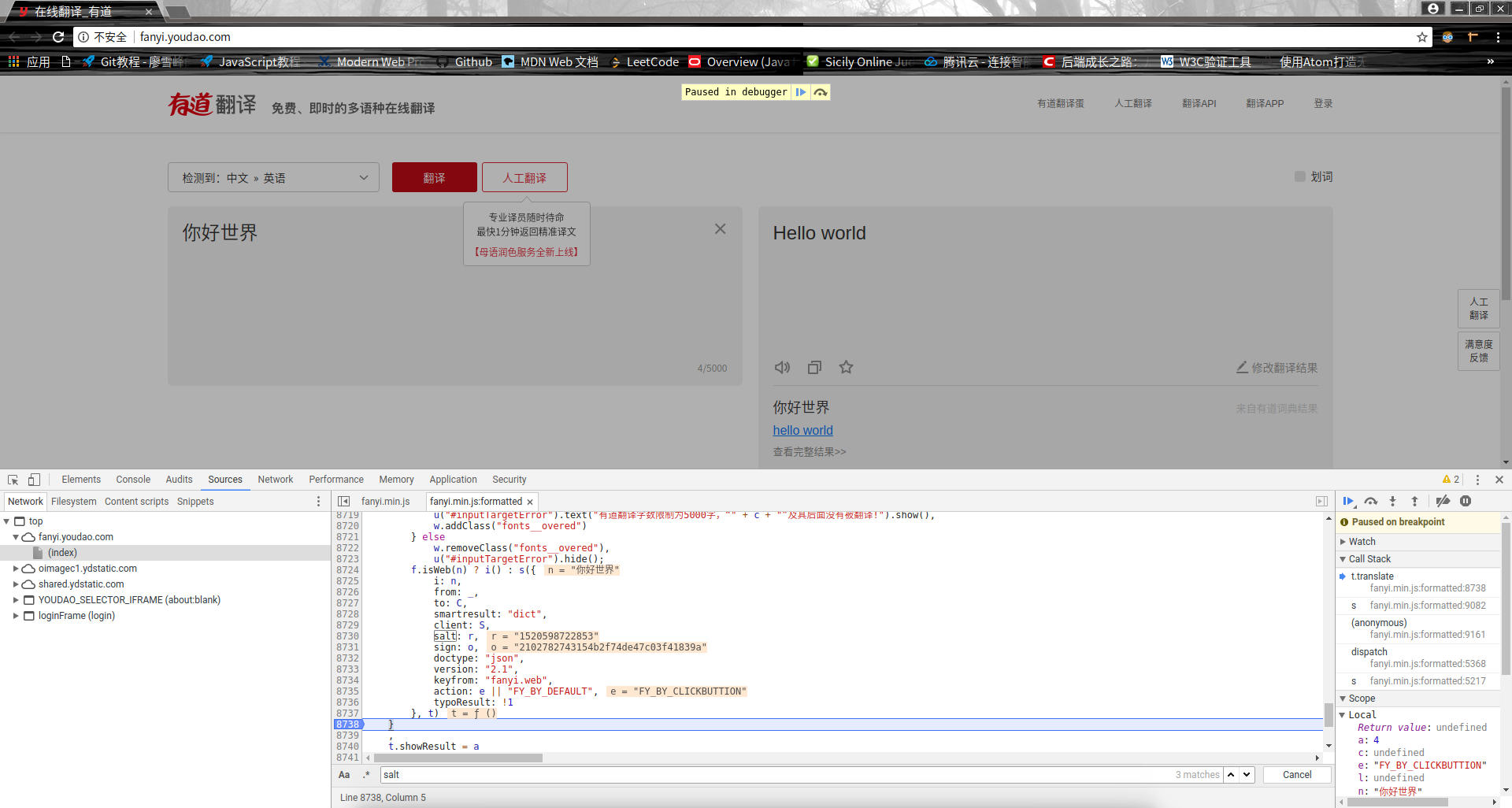
OK!我们找到了想要找的salt和sign定义的地方:
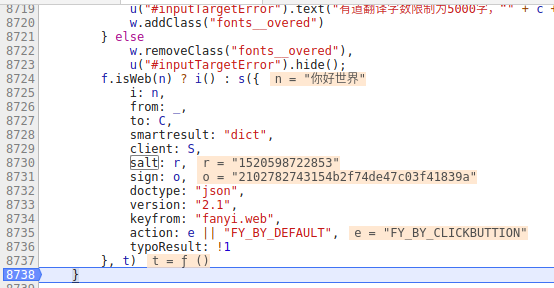
我们可以看到salt是用r赋值,值为1520598722853,sign用o赋值,值为2102782743154b2f74de47c03f41839a,我们从这个位置往上找,一般来说不会太远(毕竟只是个局部变量,定义在这个click的回调函数里面的)。
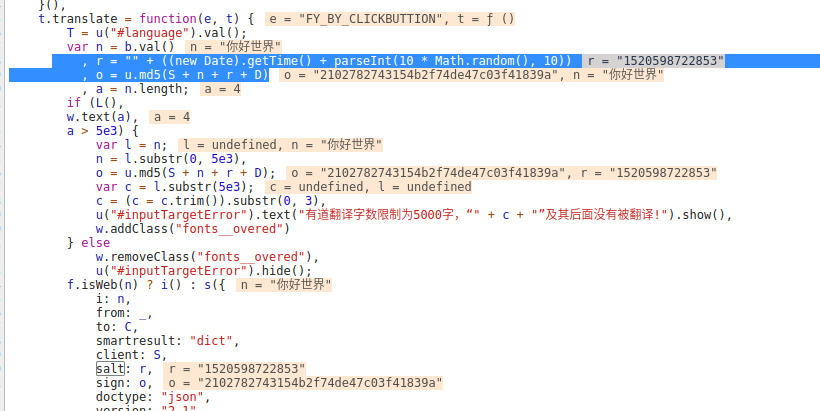
果然不出我们所料,就在上面不远的地方,查看到它俩的定义方式:
1 | r = "" + ((new Date).getTime() + parseInt(10 * Math.random(), 10)) |
r变量好理解,它是利用时间戳和一个随机数得到的。o是利用了md5加密r和另外三个变量,无奈之下我们只能看一下另外三个变量的内容是什么,做法很简单,鼠标选中这些变量查看或者添加到watches即可:
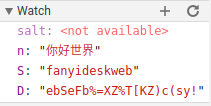
n是翻译的内容,S和D又是什么鬼?没关系,我们继续向上找,总不会找的很远的毕竟应该还在这个回调函数里面,如果是全局的变量的话就更不用怕了,全局就意味着很可能是个常量,当然这都是一些猜想,真正怎么实现的还得看有道的程序员(话说我想吐槽一下为啥变量名都用这些一个个的字母):
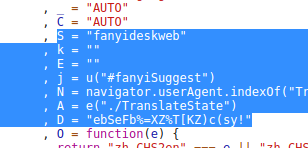
OK!果不其然,我们要找到了,更幸运的是这次是两个常量了,非常的舒服(当然在你那里是否跟我一样我就不确定,甚至有可能会被定期修改,暂时不用想那么多)。我们已经知道了js的代码是如何生成salt和sign这两个变量的,用python代码如何实现呢?你可以在python终端页面中一步步测试,这里就不这么麻烦了,我直接给最终结果吧:
1 | ########## 记得把这些模块包含进去,放在开头 |
把这两行代码插在刚刚修改payload['i']的下方,最终函数内容:
1 | def translator(input_str): |
运行结果:
1 | dreamhh@dreamhh-PC:~/Documents/Code/Python3/spidy$ python3 youdao.py |
OK!很完美的运行起来了~
总结
其实感觉用到的知识并没有很多,比如如果返回的数据不是一个JSON字符串而是一个html网页怎么办?如何处理html文件,bs4模块了解一下,它里面的BeautifulSoup对象能解析html的文档结构,进而操作每一个元素。当然还有很多很多的知识,以后我也会写写关于别的爬虫,也希望能向大家学习。
关于这篇博客的完整代码我放在github中,可以点开链接查看。
最后感谢有道翻译为我们做出的贡献和给我们出的难题(一年前的时候明明还没有salt和sign的说)。