
学会使用bs4。
废话都在前面的博客说完了,这次不说了。嗯,就说一句,仅做学习使用,看小说请支持正版。
需求说明
将网页上的小说爬取下来,并保存到本地的文件夹。
模块
这次依旧使用requests来爬取,核心思路是获取小说主页的html,然后解析html获取每一章节的url,进入url后爬取文字并写入本地文件。解析html需要用到bs4模块的BeautifulSoup类,为了避免网页编码问题需要用到chardet模块解析编码,若在本地没有这些模块用pip安装即可。
开始
抓包
好的,那么就正式开始吧!第一步依旧是抓包,我们在网上找到一个小说网站,选一本你喜欢的小说,来到首页。
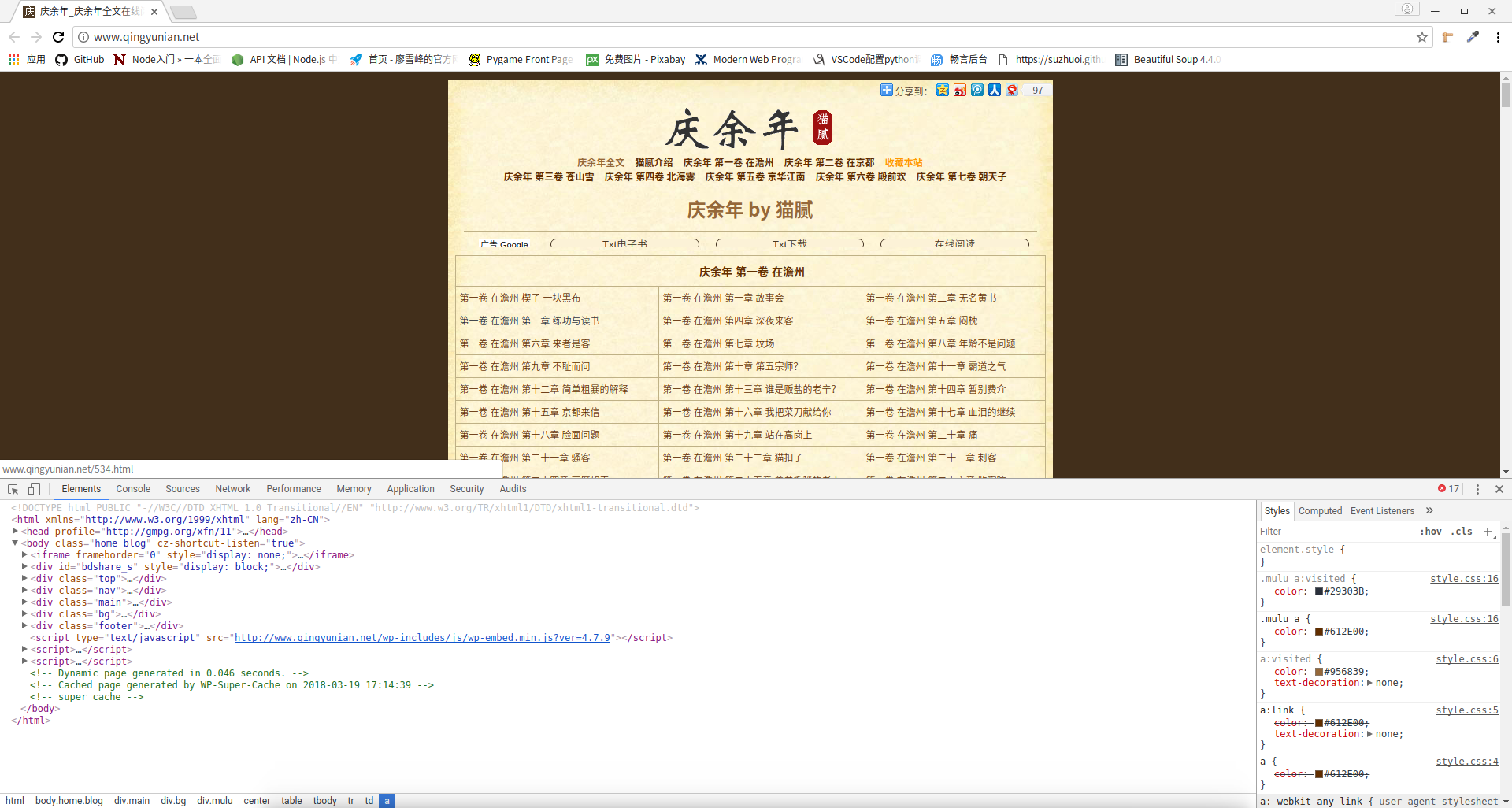
需要分析什么呢?其实什么都不用分析,因为什么都不用提交嘛。我们想要的只是首页的html罢了,怎么获取html呢?输入网址即可。
Coding
因为我们什么都不用提交,所以只是Get(如果点进Network也可一看到是清一色的Get),换句话说,我们只需要调用requests的get方法即可,传入的参数是首页的url。
1 | import requests |
我们来看看返回的数据是什么:
这一看是html没错了,但内容怎么不是中文啊?一看是乱码就不用想了,肯定又是编码问题,怎么回事呢?(如果你的没问题,说明你选的网站还算善良地告诉你了这个网页的charset)
编码问题产生的原因
这部分其实可以不用看,只是想满足一下某些人的好奇心。想直接看解决方案就可以跳过这一部分。
上面的步骤中我们的rsp.text并不是我们想要的中文内容,想知道原因那么不妨打开requests的源代码看一看,首先要知道你的requests安装在哪里,这很简单,交互界面输入:
1 | import requests |
拉到最下面的FILE部分可以看到这个路径,接下来建议用VSCode打开requests的目录,如果没有不妨下载一个,因为VSCode确实好用,经过简单配置就能成为一个很好用的IDE。打开后我的是如下界面:
左侧的就是requests模块的代码,还记得我们的目的吗?找到rsp.text,查看它的实现方式,如果你会VSCode不妨自己先试着操作一下,如果你是第一次用那就跟我一起做一次就会了:
- 随意点开左侧一个文件,按下
Ctrl+f(f是find的缩写,意为查找,还记得在浏览器中也是这么查找的吧,而且大多数编辑器都应该有这个快捷键),在右上角出现的输入框中输入我们想查找的text属性,然后回车啪一下:
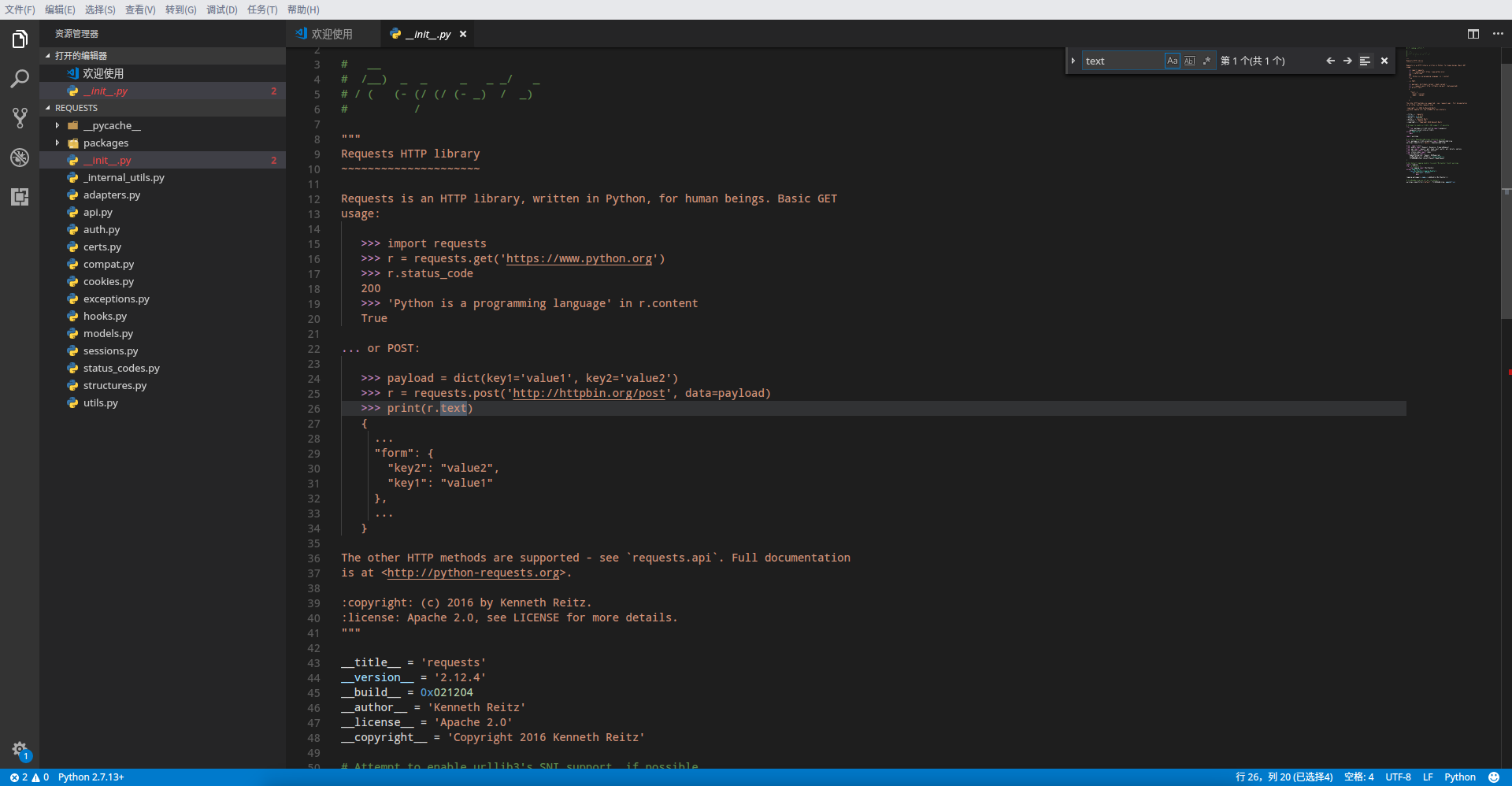
- 很不幸第一个文件的
text不是我们想要的内容,不要气馁,继续点击左侧的文件,查找会继续进行,如果这个文件没有则会显示无结果,如果有多条内容则点击输入框旁边的左右方向键来逐一查看,最终我们在models文件中找到了想要看的内容:
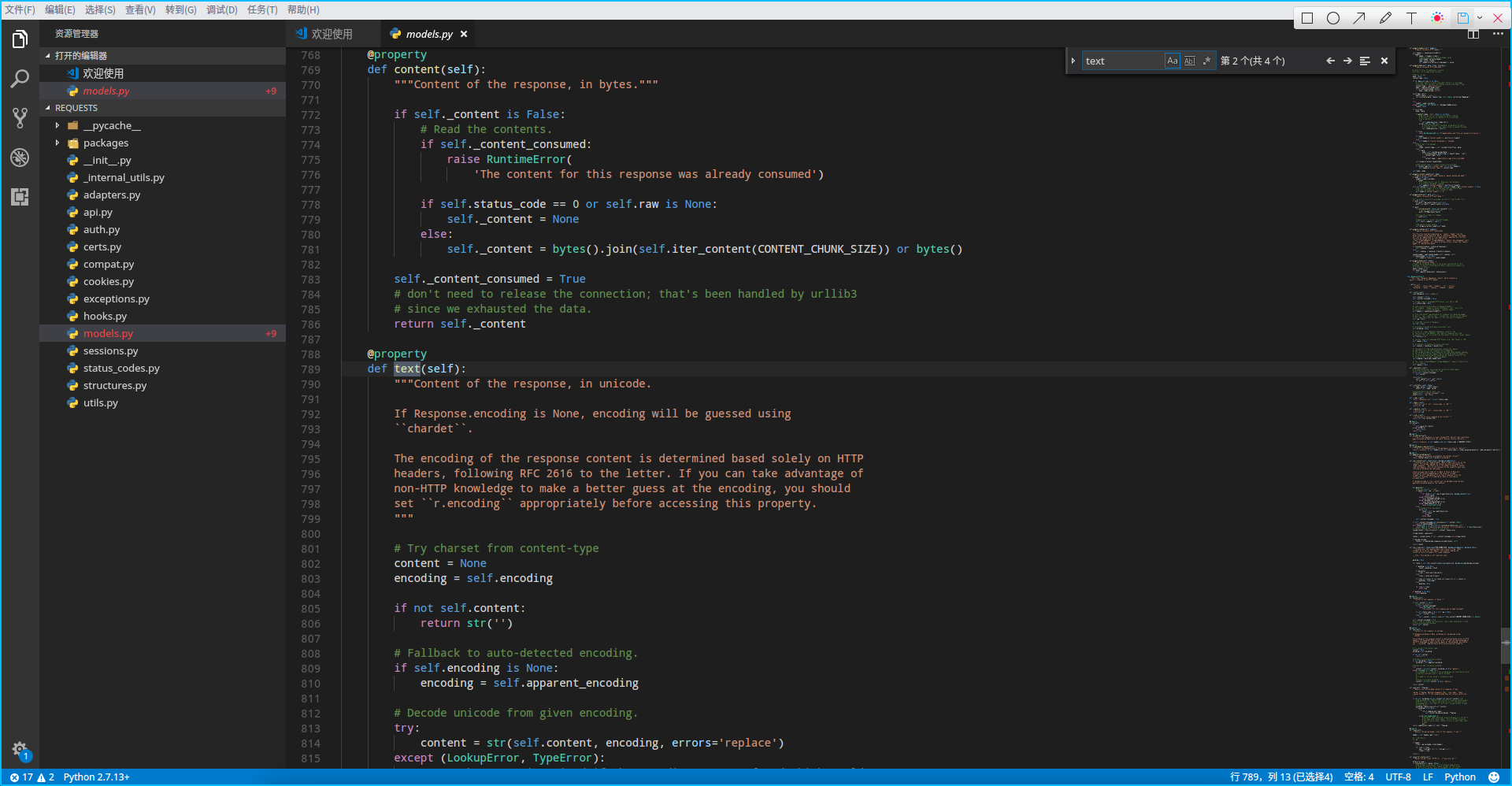
1 | def text(self): |
可以看到它最后的返回值是str(self.content, encoding, errors='replace'),也就是对self.content按照encoding解码得到的字符串,self.content显然就是字节码了(希望你知道python3的bytes和str之间的关系以及如何转换)。这里稍微解释下self.content是从服务器所获得数据(也就是首页的html)的字节码,所以关键就在于我们应该采用何种字符集去解码,而我们之前所得到的乱码显然是因为采用了错误的字符集!
从上面的代码中我们可以看到,self.text所采用的字符集encoding是self.encoding或self.apparent_encoding(当前者为None时采用后者),我们不妨看看刚刚得到的rsp的这两个属性值是什么:
1 | >>> rsp.encoding |
一看这两个居然不一样,而且你仔细感觉输入到输出的时间,应该发觉第二个会相对慢一点产生输出。我们不妨先看看apparent_encoding是如何产生的,方法很简单,按住Ctrl并点击apparent_encoding,VSCode就会帮你转到定义,你应该看到了:
1 |
|
没错,它使用了chardet.detect()这个方法,这个方法参数是字节码,返回这个字节码所采用的最可能的字符集以及可能性所构成的字典,这里返回了它的分析结果,但这个方法比较慢,所以你看到刚刚是先判断self.encoding如果None才会调用这个方法。
其实到这里就已经知道如何解决了,只要在我们自己的代码中用apparent_encoding得到的字符集解码self.content就行了。但如果你想知道self.text是如何得到那个奇怪的ISO-8859-1,可以跟我继续看看源代码。
我们知道self.encoding是ISO-8859-1了,关键是它在哪里被赋值成这个的呢?右键这个变量,点击查找所有引用:
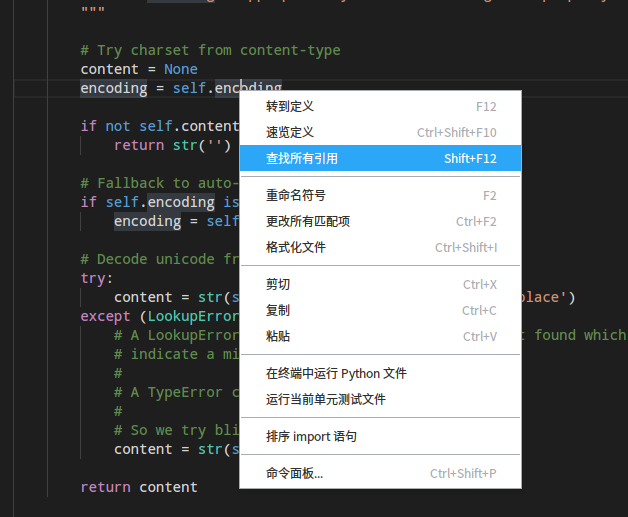
看到VSCode帮你列出来的,甚至很贴心的帮你找到了在别的文件中对这个值的引用,真的是很智能有木有,我们重点找一下赋值语句:
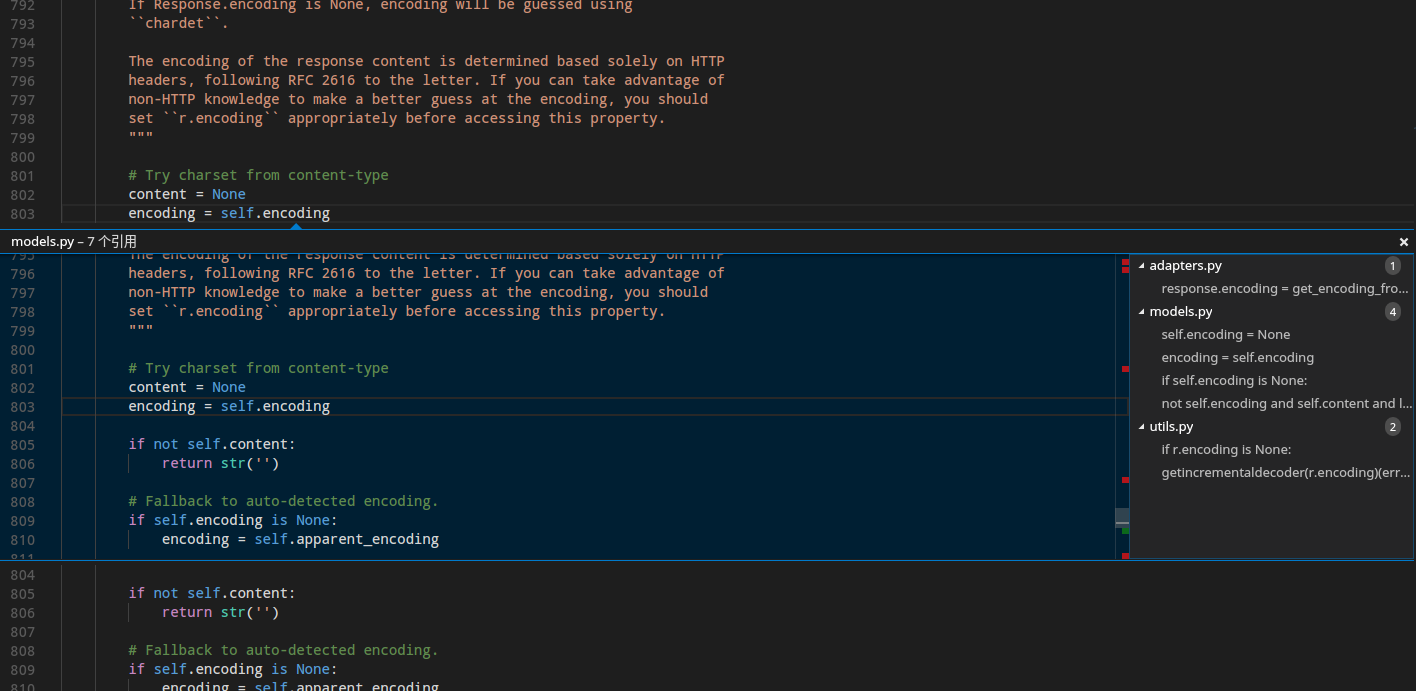
显然不会是赋为None的那几个,我们点开第一个,双击直接跳到那里,看到这个语句:response.encoding = get_encoding_from_headers(response.headers)。
相信你也猜到下一步了,那就是查看这个函数的定义,如果你直接点转到定义应该会直接跳到开头的from,所以我们不妨点刚刚用到的查看所有引用,直接看在别的文件中的位置,找到def开头的那个,毕竟这才是定义:
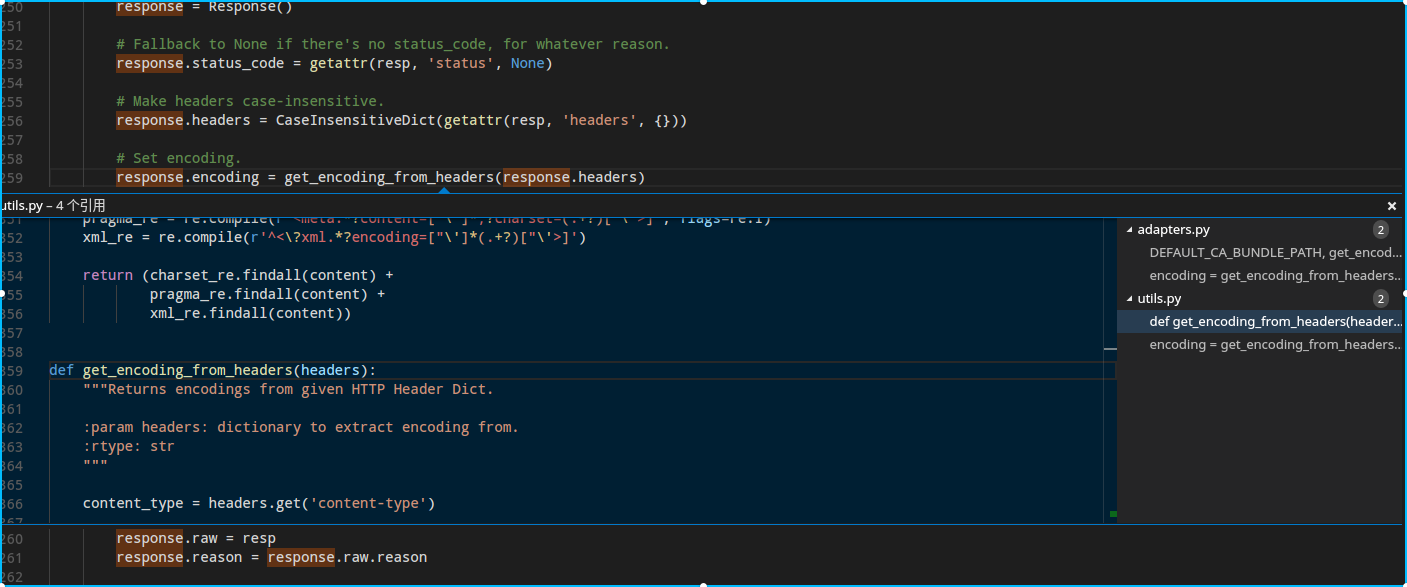
依旧双击那条选项跳到函数定义的地方:
1 | def get_encoding_from_headers(headers): |
所得死内!这下谜底揭晓了,通过注释以及源代码可以看到,它获取html编码的主要途径是headers,也就是响应首部信息。如果没有content-type则返回None(然后后期才会调用apparent_encoding),如果有content-type就检查有没有charset,有的话就用提供的编码,没有的话就用ISO-8859-1(估计这编码是作者老家用的)。
然后你只需要看看返回的响应首部是不是符合你的猜想,在Network中点开对首页的请求报文:
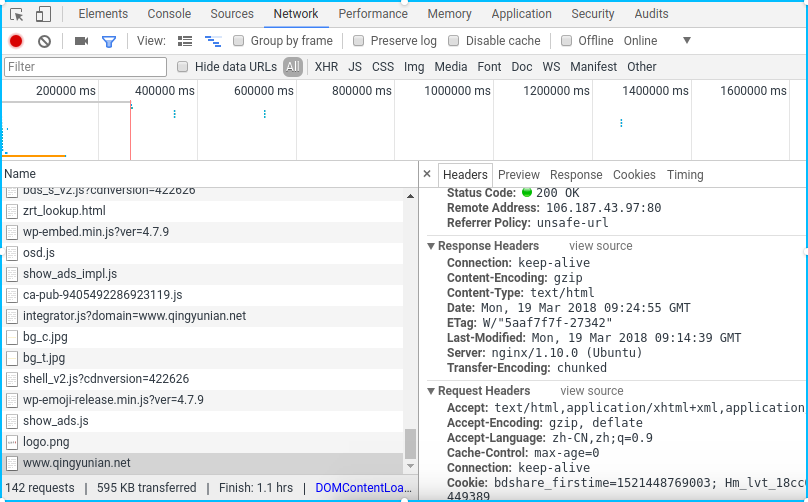
Response Headers果然有Content-Type但没说明charset。
解决编码问题
我们知道rsp.content是返回数据的字节码,只需要用合理的字符集进行解码即可,如何分析它的编码呢?这就要用到chardet模块的detect方法了,不妨在交互界面测试一下:
1 | chardet.detect(rsp.content) |
原来是utf-8,丫老熟人了。所以我们可以这么干:
1 | import requests |
部分输出效果:
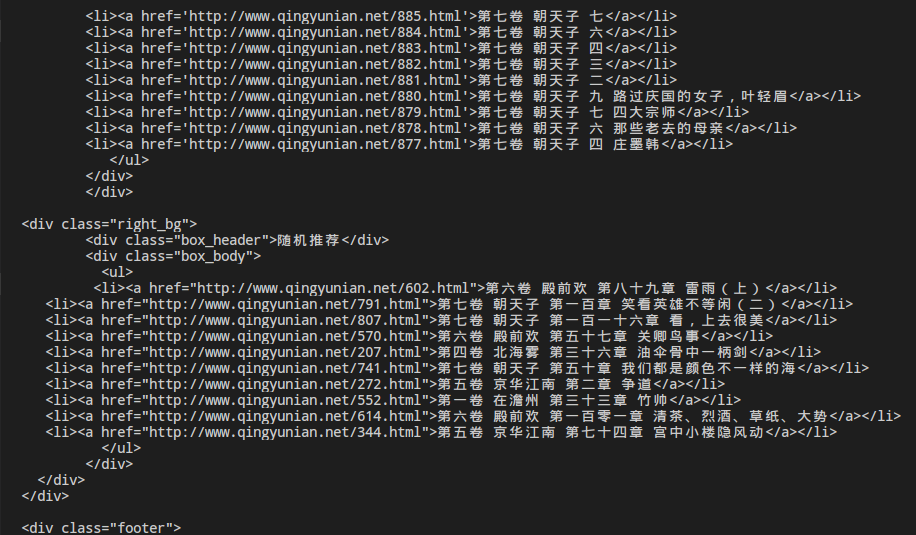
OK!总算得到我们想要的html了!
PS:如果你看了上面那部分,你应该知道这是采取了和apparent_encoding一模一样的做法,所以你还可以这么写,两种写法是等效的:
1 | import requests |
下一步就是关于如何解析我们得到的html了,也就是如何使用BeautifulSoup。你会发现有了BeautifulSoup大大简化了我们的工作。
未完待续…