
解析HTML
在开始之前先对上次的代码进行处理:
1 | import requests |
检验一下,结果和上次应该是一样的,我们只是进行了一点封装。接下来我们的目的是获取每一章节的网站:
最简单的思路是用字符串查找或正则表达式,但光想想就已经很麻烦了,一个小说几百章节一个一个找不是很麻烦吗?所以这里就用到了BeautifulSoup,它是bs4模块中的对象,可以十分方便的解析HTML文件,可以把元素内容直接获取下来,而且查找方便(简直和js的dom一样爽,不过js操作起来更方便一些)。这里就不详细说如何使用了,具体教程可以看Beautiful Soup ,中文教程看起来也比较快快。
首先我们要导入BeautifulSoup类,通过语句
1 | from bs4 import BeautifulSoup |
然后我们开始创建BeautifulSoup对象,html是我们get_HTML()函数爬下来的代码:
1 | soup = BeautifulSoup(html, 'lxml') |
OK!既然准备工作已经做的差不多了,我们再来明确一下我们的下一个目标:把章节名和链接提取出来,并分别保存在两个列表中。保存章节名为了等会我们保存成文件的时候方便命名。我们先添加这个方法:
1 | def get_chapter_links(self): |
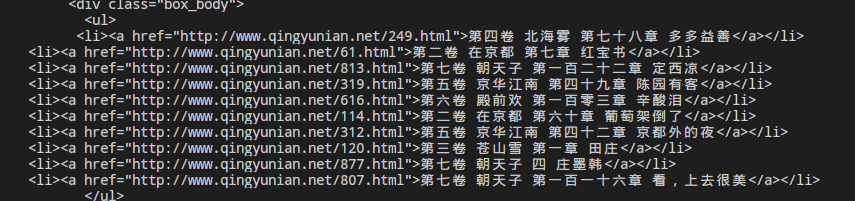
接下来我们需要在这个html中找到我们的目标——那些个章节。回到浏览器中,我们打开小说网页后,右键点击其中一个章节,并点击检察,浏览器已经自动帮我们找到他们的位置了:
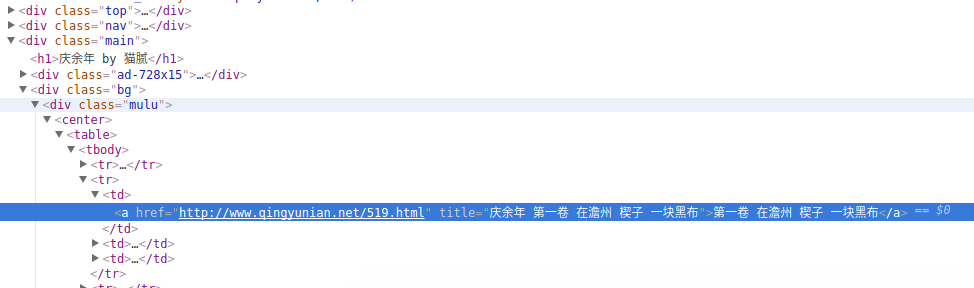
我们看到,这些链接都位于<table>标签子孙标签中,而且如果你仔细看,甚至还能发现不同的卷的章节位于不同的<table>中,但终归是<table>(你的网站可能和我用的不一样,需要自己找找规律)。
可以现在交互界面测试一下获取链接的过程:
1 | soup = BeautifulSoup(html, 'lxml') |
find_all()方法返回了所有<table>标签的列表,一共有七个,恰好对应七个卷!我们测试了一下,果然如此。
我们如何获取所有的链接呢?继续往下看:
1 | links = tables[0].find_all('a') |
我们以第一个表格为例,继续对它用find_all()方法就可以了!我们想要获取的链接就在<a>标签的href属性中,而标题就是它的内容,也就是string了!那么如何访问到这两个值呢?如下:
1 | links[0]['href'] |
这里注意一个地方,就是每个表格的第一个链接并不是章节,而是卷名!(从上面的第一个标签内容就可以看到),也就是下图最上面黑色的标题,它并不是我们所要的章节:
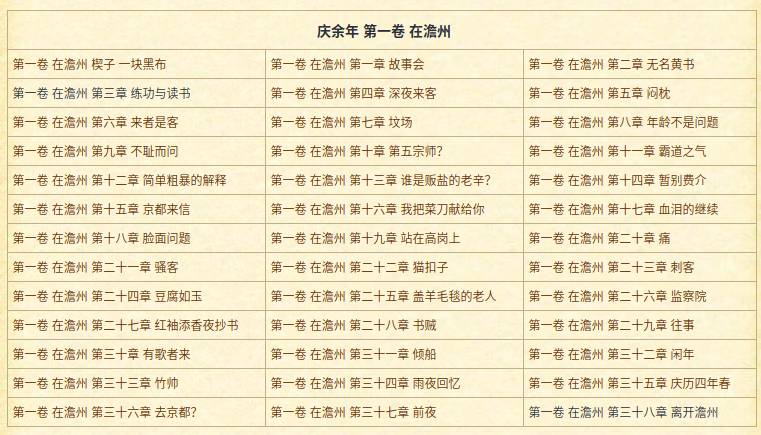
所以一会遍历的时候记得把每个表格的第一个链接不要添加进去,总结一下上面所说的内容,我们可以把上面的内容整合在一起,写出get_chapter_links()方法:
1 | def get_chapter_links(self): |
我们测试一下:
1 | if __name__ == '__main__': |
测试如图:
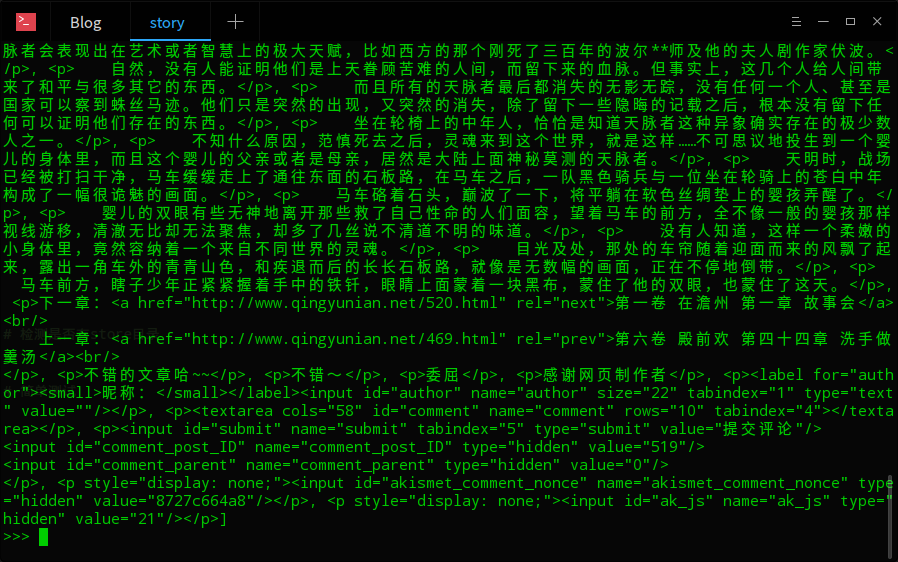
接下来我们要做的就是再进入这些链接,将里面的小说文字爬取出来。读取链接的任务就交给我们的get_HTML()函数了,所以你可以写一个新的方法read_links()。
1 | def read_links(self): |
我们检查当前文件所在的目录有没有store目录,没有就创建一个用于保存小说文件。get_HTML()用来获取链接所指向的网页内容,get_text()和write_file()是我们下面将要读取小说内容以及将小说内容保存到文件中的方法。
获取文字
具体如何获取内部的文字相信有了前面的经验以后也知道该如何去做了,我们依旧先抓包,看看文字部分位于什么样的标签下,以及如何去找到这个标签。任意进入一个章节,右键正文部分点击检察。
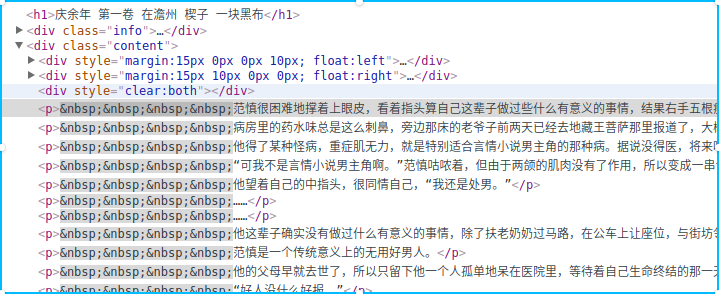
可以看到小说的主体部分位于<p>标签下,是否我们就该搜索<p>标签呢?不妨尝试一番。
这是我测试的结果,显然在最后还有一些其他的信息,那可怎么办?这里就要充分发挥我们的找规律的能力了,因为每个人所用的小说网站可能各不相同,如果你用的和我一样,就会发现: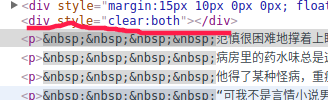
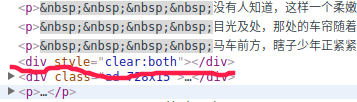
小说的正文内容用于这两个清除浮动的div块中间(不要问什么是清除浮动,前端的一点东西)!而且你查找整个页面的包含clear:both属性的标签,就只有这两个。
1 | soup.find_all(style='clear:both') |
因此我们想获取的<p>标签是这两个<div>标签之间的兄弟结点,故可以这样提取:
1 | def get_text(self, html): |
实现思路很简单,遍历<div style="clear:both"></div>后面的兄弟节点,在遇到下一个<div style="clear:both"></div>之前将所有其间元素的内容添加到字符串中,最终返回结果,返回结果的时候注意,我们把字符串中的 进行了替换,这是在html中的空格符。你可以将返回的结果测试一下,这里就不再进行示范了。
写入文件
写到文件中就更简单了,因为我们已经有了正文的字符串和每一章节的标题,这里是文件I/O的部分,不再进行细说,代码如下(写成静态方法没什么特殊原因,就是想用一下@staticmethod):
1 |
|
测试
因为章节很多所以只爬取一部分做测试,毕竟因为单进程单线程下实在是太慢了,日后用可以用一些并发的模块来做改进。废话不多说,我们只需要加一个if条件句在read_links()方法中:
1 | def read_links(self): |
测试结果如下:
收尾
OK,做到这里差不多了,这只是一个简单的爬虫,起码能大概清楚爬取一些比较简单的静态网页,但对于一些由JS生成的网页以及一些动态网页就需要更多的一些知识和模块了。以后我会慢慢去了解这些。关于这个爬虫的代码放到了我的github中,有需要可以看一看。
当然,还是那句话,仅做学习用途。