
并行让效率变得更高。
上次做的单进程爬虫如果真要用来爬我们整篇小说估计耗费的时间会比较久…来做一个粗略的估计,我们看一下爬取21章所需要的时间:
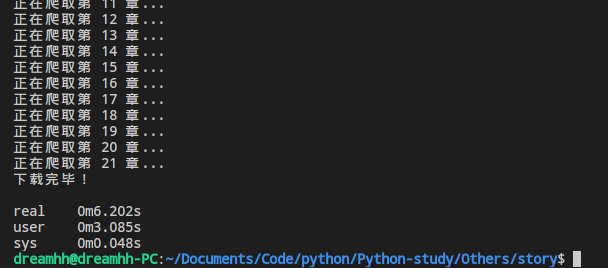
大概需要6秒,这本小说总共有780章,粗略估计下来要用230多秒,也就是4分钟左右。
接下来我们对代码稍作修改,把爬虫改装成一只多进程爬虫,每次爬取一篇文章就开一个进程。
1 | from multiprocessing import Process |
我们支队read_links()这个函数进行修改,并将爬取文章的部分取出来放到一个函数crawl里,每次循环都创建一个Process对象,即一个新的进程。我们来看看这样的效率,命令行输入time python3 xxxx.py来运行代码:
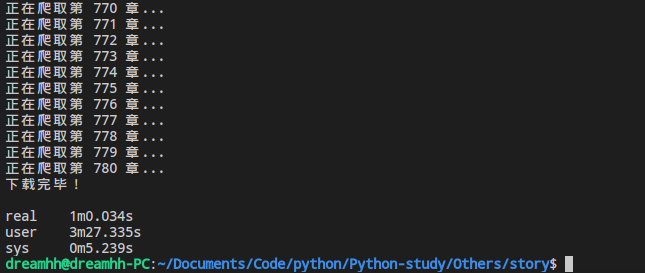
仅仅花了一分钟左右!
PS:其实本来用的是Pool(进程池),因为类的成员函数不能被pickle,弄得我非常心塞,最后就老老实实用回Process了。